Why audEERING? Revolutionizing Capital Markets Intelligence with Advanced Voice Analysis

Discover how Markets EQ, in partnership with audEERING®, is unlocking new understanding domains in capital markets through cutting-edge voice analysis technology.
Setting New Standards in Personalized Account Settings with devAIce® Speaker Verification Module

Speaker verification by audEERING® stands out because it is one of the few technologies capable of distinguishing individuals solely through voice analysis. This uniqueness is paramount, particularly when other biometric systems like facial recognition are not viable or desired.
Enhancing Communication with devAIce® ASR Module

The automatic speech recognition module from audEERING® is not just an addition to its technology range, but a decisive advance based on the fusion of ASR and vocal expression recognition. This promises to revolutionize the way we interact with machines via natural language.
Revolutionizing Expressive Intelligence with the Open-Source Expression Model – Closing the Valence Gap

Continuing our commitment to open innovation, audEERING® has made the expression model freely available on Hugging Face, which has been downloaded more than 3 million times in two years.
Open-Source Age & Biological Sex Model – A Path to Inclusive Technology

audEERING®, a leader in voice analytics technologies, has embarked on a strategic journey, offering both open-source models and commercial solutions. This blog series will explore the innovative open-source models for age & biological sex detection, and expression analysis.
Exploring the Evolution of Speech Recognition: From Audrey to Alexa
The field of speech recognition has seen remarkable evolution, driven by a quest to make machines understand and process human language as naturally as we do. This journey, marked by key innovations and transformative breakthroughs, illustrates our progressive mastery over machine-based communication.
Unveiling the Power of devAIce® SDK 3.11 and devAIce® Web API 4.4: A Deep Dive into the Latest Modules

We are excited to announce a major release of the devAIce® SDK version 3.11, as well as devAIce® Web API 4.4, a milestone that brings plenty of enhancements and new features to empower developers in creating cutting-edge audio applications.
audEERING at VOICE & AI in Washington D.C.

We are thrilled by our days at VOICE & AI | SEPT 5-7 2023, Washington D.C.
Press Release: audEERING and iMotions collaborate to refine human behavioral research
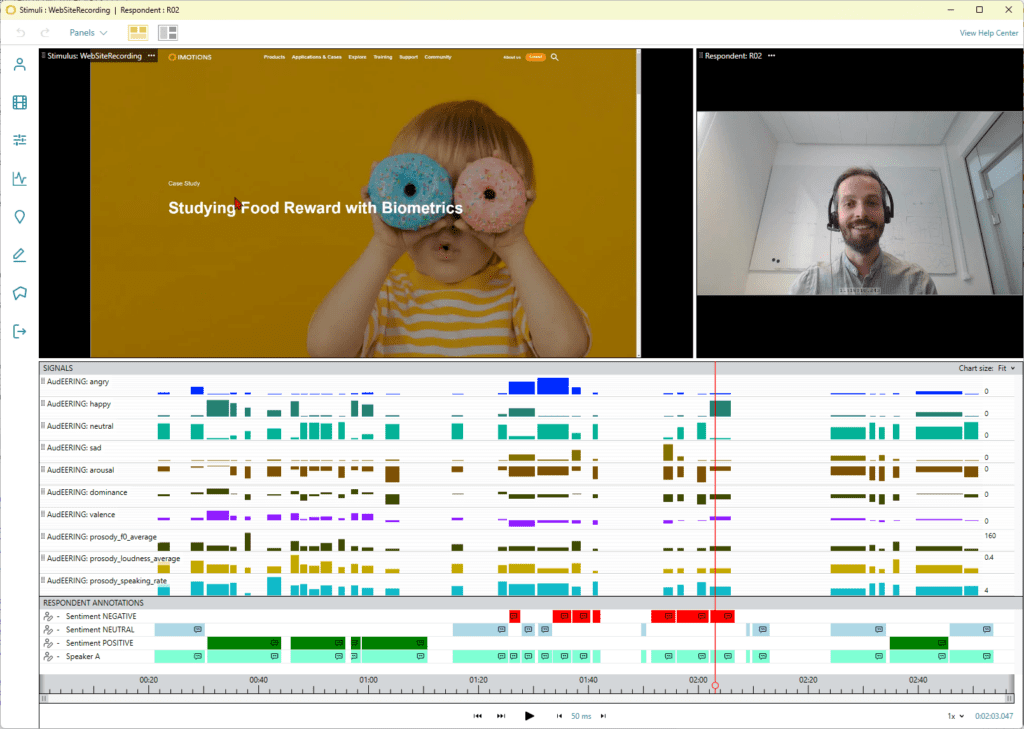
audEERING, the German market leader for AI-based audio analysis, is cooperating with iMotions, the world’s leading provider of software for interdisciplinary research into human behavior, to expand measurement and analysis areas in human science research. With the integrated voice AI component, the multimodal software suite takes on another dimension that provides insights into human behavior.
Transforming Conversational AI: Introducing ERA (Emotionally Responsive Assistant)

audEERING’s ERA demo showcasing the integration of Voice AI into conversational AI agents marks a significant milestone in the realm of affective computing. By enabling AI assistants to comprehend and respond to human emotional expression, this innovation revolutionizes our interactions with virtual companions.
devAIce® Web API 4.2 & 4.3 Updates – Exciting Additions to audEERING’s Web API

Following the recent SDK updates, we are thrilled to announce the latest enhancements in the devAIce® Web API versions. These updates bring a host of new features and improvements to empower developers in leveraging the full potential of our advanced technology. Let’s explore the exciting additions in devAIce® 4.2 and 4.3.