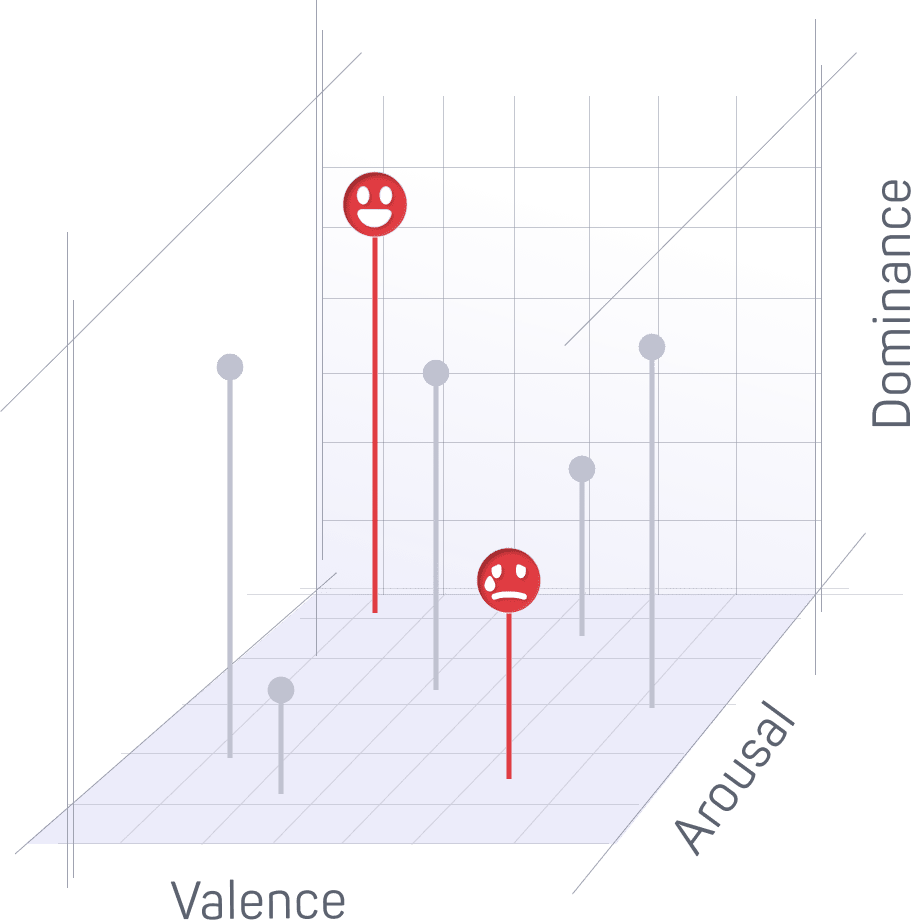
The openSMILE Features module performs feature extraction on speech. Currently, it includes the following two feature sets based on openSMILE:
This feature set consists of a total of 6373 audio features that are constructed by extracting energy, voicing, and spectral low-level descriptors and computing statistical functionals on them such as percentiles, moments, peaks, and temporal features.
While originally designed for the task of speaker emotion recognition, it has been shown to also work well for a wide range of other audio classification tasks.
The GeMAPS+ feature set is a proprietary extension of the GeMAPS feature set described in Eyben et al.2. The set consists of a total of 276 audio features and has been designed as a minimalistic, general-purpose set for common analysis and classification tasks on voice.