

2021 war ein aufregendes Jahr für unsere Forscher, die sich mit der Erkennung von Emotionen anhand von Sprache beschäftigen. Dank der jüngsten Fortschritte bei transformatorbasierten Architekturen haben wir zum ersten Mal Modelle entwickelt, die die Valenz (d. h. wie negativ oder positiv eine Äußerung klingt) mit ähnlich hoher Präzision vorhersagen wie die Erregung (d. h. wie erregt eine Äußerung klingt). Die Schließung der Valenzlücke ist eine große Herausforderung in der Sprach-Emotionserkennung (SER). Im Gegensatz zu früheren Ansätzen leiten unsere Modelle ihre Vorhersagen direkt aus dem Roh-Audio ab und benötigen keine Texttranskription.
Valenzvorhersage ohne Verwendung von sprachlichen Informationen
Der Mangel an markierten Daten ist eines der größten Hindernisse in der SER-Forschung. Um diese Einschränkung zu überwinden, haben wir unseren Schwerpunkt von spezialisierten Architekturen, die für eine bestimmte Aufgabe trainiert werden, auf allgemein einsetzbare Basismodelle verlagert. Basismodelle werden unbeaufsichtigt auf großen Datensätzen ohne Beschriftungen trainiert und anschließend auf (kleinen) Datensätzen mit Beschriftungen für die vorgesehenen Aufgaben feinabgestimmt. In einer gemeinsamen Publikation von audEERING und dem Lehrstuhl für Eingebettete Intelligenz für Gesundheit und Wohlbefinden (Universität Augsburg) unter der Leitung von CSO Prof. Björn Schuller, bieten wir eine gründliche Evaluierung dieses Ansatzes im Hinblick auf Generalisierung, Robustheit, Fairness und Effizienz. Das von uns vorgeschlagene System erzielt eine Spitzenleistung bei der Valenzvorhersage ohne Verwendung expliziter linguistischer Informationen, mit einem Konkordanzkorrelationskoeffizienten (CCC) von 0,638 bei MSP-Podcast.

Tutorial für weitere Analysen verfügbar
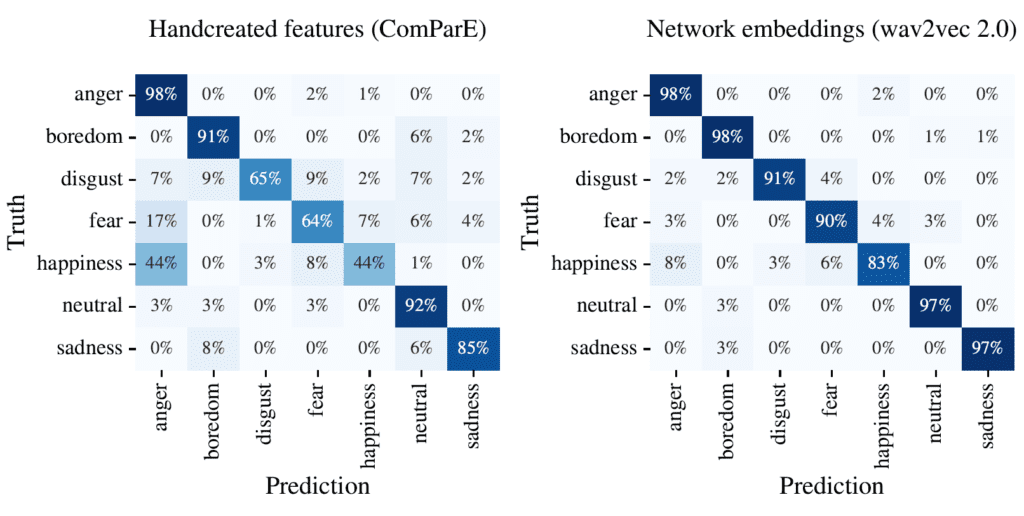
Um die Community zu ermutigen, sich mit unserem Ansatz zu messen und weitere Analysen durchzuführen, haben wir das leistungsstärkste Modell aus der Arbeit öffentlich zugänglich gemacht. Ein Tutorial zeigt, wie das Modell verwendet werden kann, und hebt eine weitere Stärke hervor: Die Ausgabe der Zwischenschichten (sogenannte Einbettungen) liefert eine kompakte Sprachrepräsentation, die sich gut auf andere Emotionsaufgaben übertragen lässt. Wir zeigen, dass die gelernten Repräsentationen sogar klassische handgefertigte Merkmale wie das beliebte ComParE 2016 Set von openSMILE übertreffen können.
Zwei Schritte voraus
Mit dem neuesten Update ist die neue Technologie bereits in unserem Produkt devAIce verfügbar.





