Ihre Stimme hat die Macht, eine natürliche Mensch-Maschine-Interaktion zu ermöglichen.
devAIce®

Einfühlsame Maschinen
Unterstützt durch Voice AI
Machen Sie Stimmen in der Mensch-Maschine-Interaktion so wichtig, wie sie es in Ihren täglichen Interaktionen sind. Mit Voice AI können sich Maschinen interaktiv, natürlich und individuell verhalten.
Das Ergebnis sind personalisierte Einstellungen, tiefe Einblicke in die Bedürfnisse der Nutzer und Empathie als KPI der Digitalisierung. Mit Voice AI wird der größtmögliche Mehrwert aus der Mensch-Maschine-Interaktion gewonnen.
devAIce® ist unsere verantwortliche Audio & Voice AI Lösung, die in zahlreichen Anwendungsfällen eingesetzt werden kann:
Software oder Hardware
Audioanalyse für jedes Produkt
devAIce® analysiert stimmliche Ausdrücke, akustische Szenen und erkennt viele andere Merkmale von Audio. Unsere KI-Modelle zeigen auch bei begrenzter CPU-Leistung eine solide Leistung. devAIce® ist für geringen Ressourcenverbrauch optimiert. Viele Modelle in devAIce® können in Echtzeit auf eingebetteten, stromsparenden ARM-Geräten wie dem Raspberry Pi und anderen SoCs laufen.
Apps, Programme & WebanwendungenIoT-GeräteWearables & Smart DevicesVoice Bots & Conversational AI ToolsAutomotive IoTXR-Projekte mit Unity & Unreal Plugin
Vorherige Folie
Nächste Folie
devAIce® die Kerntechnologie
Mehrere Module enthalten
devAIce® umfasst insgesamt 11 Module, die je nach Anwendung und Kontext kombiniert und eingesetzt werden können. Werfen Sie einen Blick auf das devAIce® Factsheet oder scrollen Sie durch die Modulübersicht für weitere Informationen.
Factsheet
Erkennung von Sprachaktivität (VAD)
Das VAD-Modul erkennt das Vorhandensein von Sprache in einem Audiostrom. Die Erkennung ist sehr robust gegenüber Rauschen und unabhängig vom Lautstärkepegel der Stimme. Das bedeutet, dass auch leise Stimmen in Anwesenheit von lauteren Hintergrundgeräuschen erkannt werden können.
Die Erkennung von Sprache in großen Mengen von Audiomaterial führt zu einem ressourcenschonenden und effizienten Analyseprozess. Wenn VAD vor der eigentlichen Sprachanalyse läuft, können große Mengen von Nicht-Sprachdaten gefiltert und von der Analyse ausgeschlossen werden.
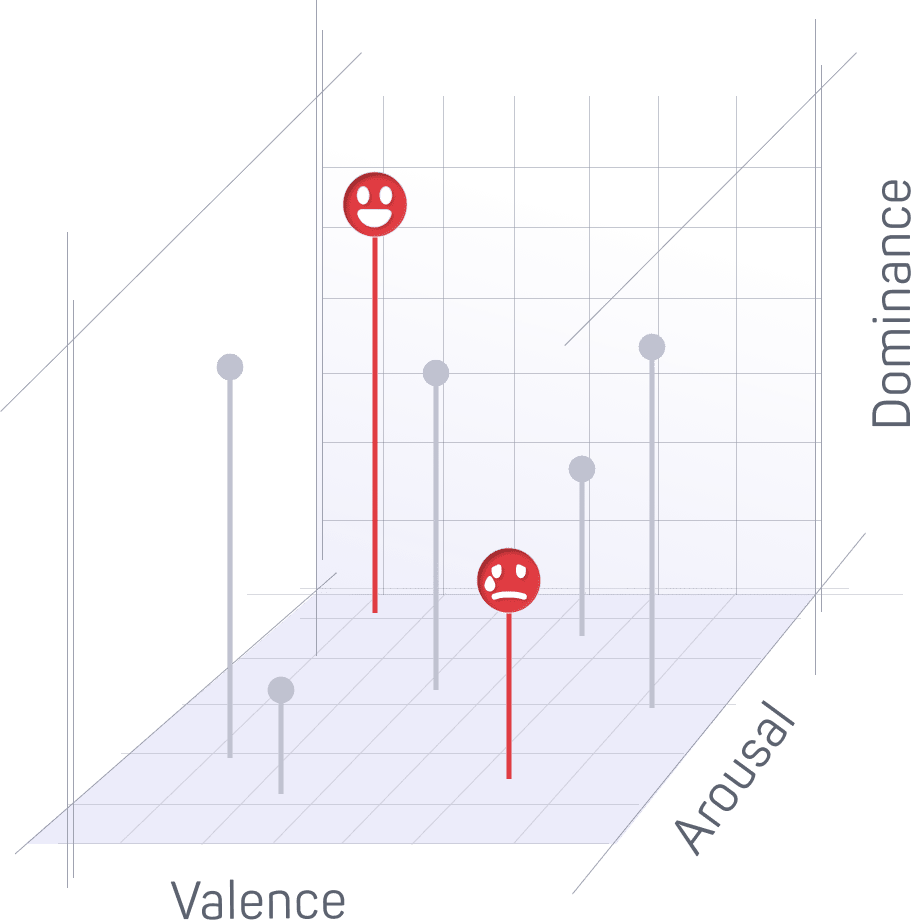
Das Modul Expression analysiert den Ausdruck von Emotionen in der Stimme. Das Modul wurde entwickelt, um den Ausdruck in allen Sprachen zu analysieren. Derzeit kombiniert das Modul zwei unabhängige Ausdrucksmodelle mit unterschiedlichen Ausgabedarstellungen:
- Ein dimensionales Erregungs-Valenz-Dominanz-Ausdrucksmodell
- Ein vierstufiges kategorisches Ausdrucksmodell: glücklich, wütend, traurig und neutral
In devAIce® bieten wir zwei Expression-Module an: Expression und Expression Large.
Wenn Sie mit begrenzten Rechenressourcen arbeiten oder Ihre Anwendung auf Geräten mit geringerer Speicherkapazität ausführen, ist das Expression-Modul besser für Ihre Bedürfnisse geeignet als das Expression Large-Modul, das eine höhere Vorhersagegenauigkeit aufweist.
Das Modul Multi-Modal Expression kombiniert akustische und linguistische Ausdrucksanalyse in einem einzigen Modul.
Es erreicht eine höhere Genauigkeit als Modelle, die nur auf eine der Modalitäten beschränkt sind (z. B. das Modell des Moduls "Ausdruck"). Akustische Modelle sind tendenziell besser in der Lage, die Erregungsdimension des Ausdrucks abzuschätzen, während linguistische Modelle bei der Vorhersage der Valenz (Positivität/Negativität) besser abschneiden. Das Modul Multi-Modal Expression fusioniert Informationen aus beiden Modalitäten, um die Vorhersagegenauigkeit zu verbessern.
Das Acoustic Scene Module unterscheidet zwischen 3 Klassen:
- Innenbereich
- Draußen
- Transport
Weitere Unterklassen werden in jeder akustischen Szenenklasse erkannt. Dieses Modell befindet sich derzeit in der Entwicklung - die spezifischen Unterklassen werden im nächsten Update benannt.
Akustische Ereignisdetektion (AED)
Das AED-Modul führt eine akustische Ereigniserkennung für mehrere akustische Ereigniskategorien in einem Audiostrom durch.
Derzeit werden die akustischen Ereigniskategorien Sprache und Musik unterstützt. Das Modell erlaubt es, dass sich Ereignisse verschiedener Kategorien zeitlich überschneiden.
Das Modul Sprecherattribute schätzt die persönlichen Attribute von Sprechern anhand von Stimme und Sprache. Diese Attribute umfassen:
- A wahrgenommen Geschlecht (Geschlecht), unterteilt in die Kategorien:
- weibliche Erwachsene
- männlicher Erw achsener
- Kind
- A gefühltes Alter, in Jahren
devAIce® bietet zwei Gender-Submodule namens Gender und Gender (Small).
Die Alters-Geschlechts-Modelle werden anhand des selbst angegebenen Geschlechts trainiert.
Aufbauend auf der Grundlage des vorherigen Moduls zur Sprecherüberprüfung (Beta-Version) haben wir das zugrunde liegende Modell durch ein neues ersetzt, das auf den neuesten Deep-Learning-Architekturen basiert. Dies führte zu einer bemerkenswerten Steigerung der Genauigkeit und zu einer signifikanten Senkung der Equal Error Rate (EER) auf nur 4,3 %, eine Leistung auf dem neuesten Stand der Technik.
Sie können nun eine robustere Sprecherverifizierung erreichen, indem Sie einen einzelnen Sprecher zuverlässig verifizieren und so die Grenzen des bisher Möglichen erweitern.
- Enrollment-Modus: Ein Sprechermodell für einen Referenzsprecher wird auf der Grundlage einer oder mehrerer Referenzaufnahmen erstellt oder aktualisiert.
- Verification-Modus: Ein zuvor erstelltes Sprechermodell wird verwendet, um abzuschätzen, wie wahrscheinlich es ist, dass derselbe Sprecher in einer bestimmten Aufnahme vorhanden ist.
Es ist wichtig zu beachten, dass aufgrund des neuen zugrundeliegenden Modells die Ressourcennutzung und die Rechenkosten des Moduls Speaker Verification steigen.
Das Prosody-Modul berechnet die folgenden prosodischen Merkmale:
- F0 (in Hz)
- Lautstärke
- Sprechgeschwindigkeit (in Silben pro Sekunde)
- Intonation
Ausführung des Prosody-Moduls in Kombination mit VAD:
- Wenn das VAD-Modul deaktiviert ist, wird der gesamte Audio-Input als eine einzige Äußerung analysiert und ein Prosodie-Ergebnis erzeugt.
- Wenn der VAD aktiviert ist, wird der Audioeingang zunächst durch den VAD segmentiert, bevor das Prosody-Modul für jedes erkannte Sprachsegment ausgeführt wird. In diesem Fall werden einzelne Prosodie-Ergebnisse für jedes Segment ausgegeben.
Das openSMILE-Features-Modul führt die Merkmalsextraktion für Sprache durch. Derzeit enthält es die folgenden zwei auf openSMILE basierenden Merkmalssätze:
- KomParE-2016
Dieser Merkmalsatz besteht aus insgesamt 6373 Audiomerkmalen, die durch Extraktion von Energie-, Stimm- und spektralen Low-Level-Deskriptoren und die Berechnung von statistischen Funktionen wie Perzentilen, Momenten, Spitzen und zeitlichen Merkmalen erstellt werden.
Ursprünglich wurde es für die Erkennung von Emotionen bei Sprechern entwickelt, es hat sich jedoch gezeigt, dass es auch für eine breite Palette anderer Audioklassifizierungsaufgaben gut geeignet ist.
- GeMAPS+
Der GeMAPS+-Merkmalssatz ist eine proprietäre Erweiterung des in Eyben et al.2 beschriebenen GeMAPS-Merkmalssatzes. Der Satz besteht aus insgesamt 276 Audio-Merkmalen und wurde als minimalistischer, allgemeiner Satz für gängige Analyse- und Klassifizierungsaufgaben von Sprache konzipiert.
Automatische Spracherkennung (ASR)
Durch die Nutzung der leistungsstarken whisper.cpp-Bibliothek eröffnet dieses Modul eine Welt der Möglichkeiten, indem es Entwicklern erlaubt, gesprochene Sprache nahtlos in geschriebenen Text zu transkribieren. Die zusätzliche Integration dieses Moduls bedeutet, dass Ressourcen nicht mehr verwendet werden müssen, um externe ASR-Engines separat zu integrieren und mit der Audioanalyse zu kombinieren, da devAIce® eine All-in-One-Lösung bietet.
Das Modul Audioqualität schätzt das Signal-Rausch-Verhältnis (SNR) und die Nachhallzeit (RT60) eines gegebenen Audioeingangs. Es werden Eingangssignale beliebiger Dauer akzeptiert. Jeder Audioeingang liefert einen Wert für jeden Parameter.
 Ausdruck
Ausdruck Voice Activity
Voice Activity Sprecher-Attribute
Sprecher-Attribute Akustische Szene
Akustische Szene
Persönlicher Ausdruck Der Ton der Stimme
Der persönliche Ausdruck wird über die Stimme vermittelt. In unserem Alltag führen wir automatisch eine auditive Analyse durch, wenn wir mit jemandem sprechen. devAIce® konzentriert sich auf den stimmlichen Ausdruck und leitet aus der Stimmanalyse emotionale Dimensionen ab.
Erkennung von Sprachaktivität
Stimme oder Hintergrundgeräusche?
devAIce® erkennt zuverlässig die An- und Abwesenheit von Sprache in Echtzeit mit minimaler Latenz.

Sprecher-Attribute
Wer spricht? devAIce® kann Ihnen Einblicke in Rednermerkmale wie Alter oder Geschlecht geben.

Akustische Szenendetektion
Wo befinden Sie sich? devAIce® kann 3 akustische Klassen unterscheiden - Innen, Außen, Verkehr. Das Modul analysiert konkrete akustische Szenen für jede akustische Klasse.
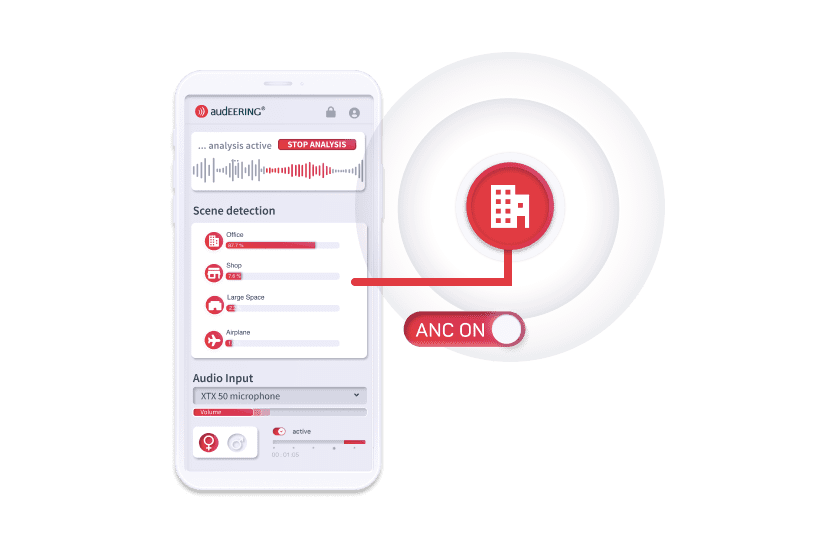

Engage AI von Jabra
Powered by audEERING
Engage AI von Jabra ist das Call Center-Tool für verbesserte Konversationen zwischen Agenten und Kunden. Die Integration von audEERINGs fortschrittlicher KI-gestützter Audio-Analyse-Technologie devAIce® in den Call Center-Kontext sorgt für eine neue Ebene der Agenten- und Kundenerfahrung. Das Tool passt in zahlreiche Kontexte, immer mit dem Ziel, die Kommunikation zu verbessern.

Quelle: https://www.jabra.com/software-and-services/jabra-engage-ai/
MW Research
Sprachanalyse in der Marktforschung
"Verbessern Sie Produkt- oder Kommunikationstests mit emotionalem Feedback! Unsere Methode analysiert den emotionalen Zustand Ihrer Kunden während der Evaluierung. So erhalten Sie einen umfassenden Einblick in das emotionale Nutzererlebnis."


Hanson Robotics
Roboter mit Einfühlungsvermögen
Die Kooperation zwischen Hanson Robotics und audEERING® zielt auch darauf ab, die sozialen Fähigkeiten von Sophia Hanson weiterzuentwickeln. Sophia soll in Zukunft die Nuancen eines Gesprächs erkennen und daraufhin empathisch reagieren können.
In der Pflege und anderen vom Fachkräftemangel betroffenen Bereichen können solche mit sozialer KI ausgestatteten Roboter in Zukunft helfen.
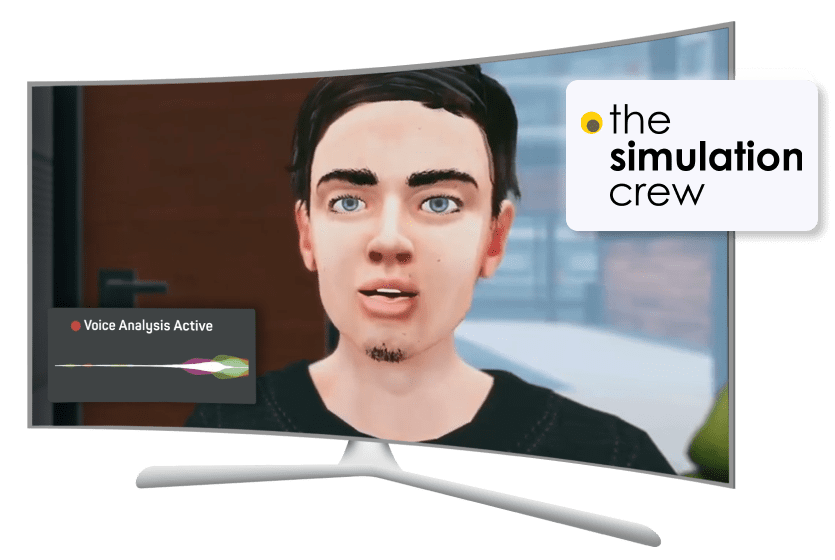
Die Simulations-Crew
"Emotionen sind ein wesentlicher Bestandteil unserer Interaktionen", sagt Eric Jutten, CEO des niederländischen Unternehmens The Simulation Crew.
Um sicherzustellen, dass ihr VR-Trainer, Iva, zur Empathie fähig ist, fanden sie devAIce® XR als Lösung. Mit Hilfe des XR-Plugins integrierten sie Voice AI in ihr Produkt. Lesen Sie die ganze Geschichte.
Holen Sie sich die Minuten, die Sie brauchen!
devAIce® Prepaid-Tarife
VORAUSBEZAHLTER EINTRITT
€
35
- 600 Minuten
- Web-API
- BASE-Paket, inkl. einem ausgewählten Modul
Hier klicken
Link zu unserem Partner "Stripe"
PREPAID PLUS
€
250
- 6.000 Minuten
- Web-API
- BASE-Paket, inkl. einem ausgewählten Modul
Klicken Sie hier
Link zu unserem Partner "Stripe"

Pakete Übersicht
BASIS
+ Erkennung von Sprachaktivität
+ Akustische Ereignisdetektion
+ Überprüfung des Sprechers
+ ASR
+ Audioqualität
+ Merkmale
AUSDRUCK
+ Stimmlicher Ausdruck
+ Vocal Expression Groß
+ Multimodale Expression
+ Prosodie
SPEAKER
+ Alter
+ Wahrgenommenes Geschlecht
SZENE
+ 3 Schauplätze mit
8 Unterszenen
+ Innen
+ Außen
+ Transport

devAIce® SDK:
leichtgewichtig,
natives On-Device
Das devAIce® SDK ist für alle wichtigen Desktop-, Mobil- und Embedded-Plattformen verfügbar. Es funktioniert auch gut auf Geräten mit geringen Rechenressourcen, wie Wearables und Hearables.
- Plattformen: Windows, Linux, macOS, Android, iOS
- Prozessorarchitekturen: x86-64, ARMv8

devAIce® Web API: Cloud-gestützt,
nativ für das Web
devAIce® Web API ist der einfachste Weg, Audio AI in Ihre web- und cloudbasierten Anwendungen zu integrieren. Vor-Ort-Einsatzoptionen für höchste Datensicherheitsanforderungen sind verfügbar. Web API zugänglich:
- über das Kommandozeilen-CLI-Tool
- über mitgelieferte Client-Bibliotheken: Python, .NET, Java, JavaScript und PHP
- durch direktes Senden von HTTP-Anfragen

devAIce® XR: das Unity & Unreal Plugin
devAIce® XR integriert die intelligente Audioanalyse in die Virtualität. Das Plugin ist so konzipiert, dass es in Ihr Unity- oder Unreal-Projekt integriert werden kann.
Verpassen Sie nicht den Moment, um den wichtigsten Teil der Interaktion einzubeziehen: Einfühlungsvermögen.
Product Owner Talk
mit Milenko Saponja
Mehrere Anwendungsfälle
Für Voice AI-Technologie
Marktforschung

Automobiles IoT

Robotik & IoT

Gesundheitswesen

Kunden, Projekte &
Erfolgsgeschichten
Kontaktieren Sie uns.
Setzen Sie sich jetzt mit audEERING® in Verbindung, um eine Demo zu vereinbaren oder zu besprechen, wie Ihre Organisation von unseren Produkten und Lösungen profitieren kann.